
Grocery Odering Prediction
Instacart - a grocery ordering and delivery app are aiming at making it easy to fill your storeroom and refrigirator with your favorites food, vegetables and fruits whenever you need them. After selecting products through the Instacart app, personal shoppers review your order and do the in-store shopping and delivery for you.
Instacart is challenging the data science community to use this anonymized data on customer orders over time to predict which previously purchased products will be in a user’s next order.
Data Description:
The dataset for this competition is a relational set of files describing customers’ orders over time. The dataset is anonymized and contains a sample of over 3 million grocery orders from more than 200,000 Instacart users.
For each user, we are provided between 4 and 100 of their orders, with the sequence of products purchased in each order. We are also provided the week and hour of day the order was placed, and a relative measure of time between orders.
“The Instacart Online Grocery Shopping Dataset 2017” can be accessed from https://www.instacart.com/datasets/grocery-shopping-2017
Project Goal:
The goal of the competition is to predict which products will be in a user’s next order. The success of this project would enable Instacart to revolutionize how consumers discover and purchase groceries online.
In this project, our focus would be on exploratory analysis designed to guide the modeling process
Relax and enjoy!
First we take a look look at a few observations from our products datasets.
Products
| product_id | product_name | aisle_id | department_id |
|---|---|---|---|
| 1 | Chocolate Sandwich Cookies | 61 | 19 |
| 2 | All-Seasons Salt | 104 | 13 |
| 3 | Robust Golden Unsweetened Oolong Tea | 94 | 7 |
| 4 | Smart Ones Classic Favorites Mini Rigatoni With Vodka Cream Sauce | 38 | 1 |
| 5 | Green Chile Anytime Sauce | 5 | 13 |
| 6 | Dry Nose Oil | 11 | 11 |
| 7 | Pure Coconut Water With Orange | 98 | 7 |
| 8 | Cut Russet Potatoes Steam N’ Mash | 116 | 1 |
| 9 | Light Strawberry Blueberry Yogurt | 120 | 16 |
| 10 | Sparkling Orange Juice & Prickly Pear Beverage | 115 | 7 |
Data Exploration
Since our interest is to predict the products that would be reordered, It’ll be great to know the proportion of reordered observations in our dataset.
The distribution below highlights the proportion of products that were reordered. 1 signifies the products were reordered whereas 0 means the product was not reordered.
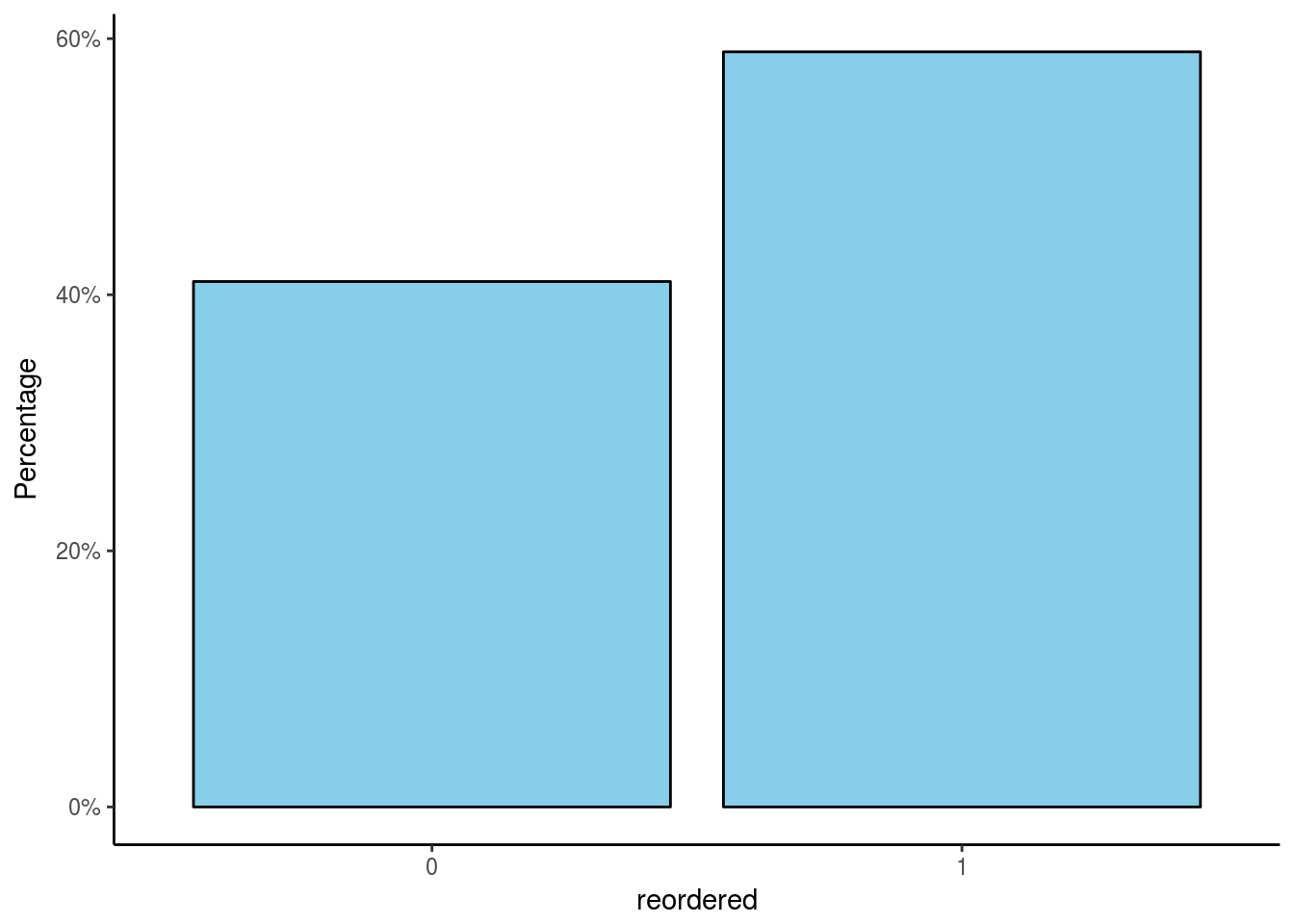
From above: About 59% of all products in our database were reordered. A faily balanced dataset I suppose.
Which products had the highest orders?
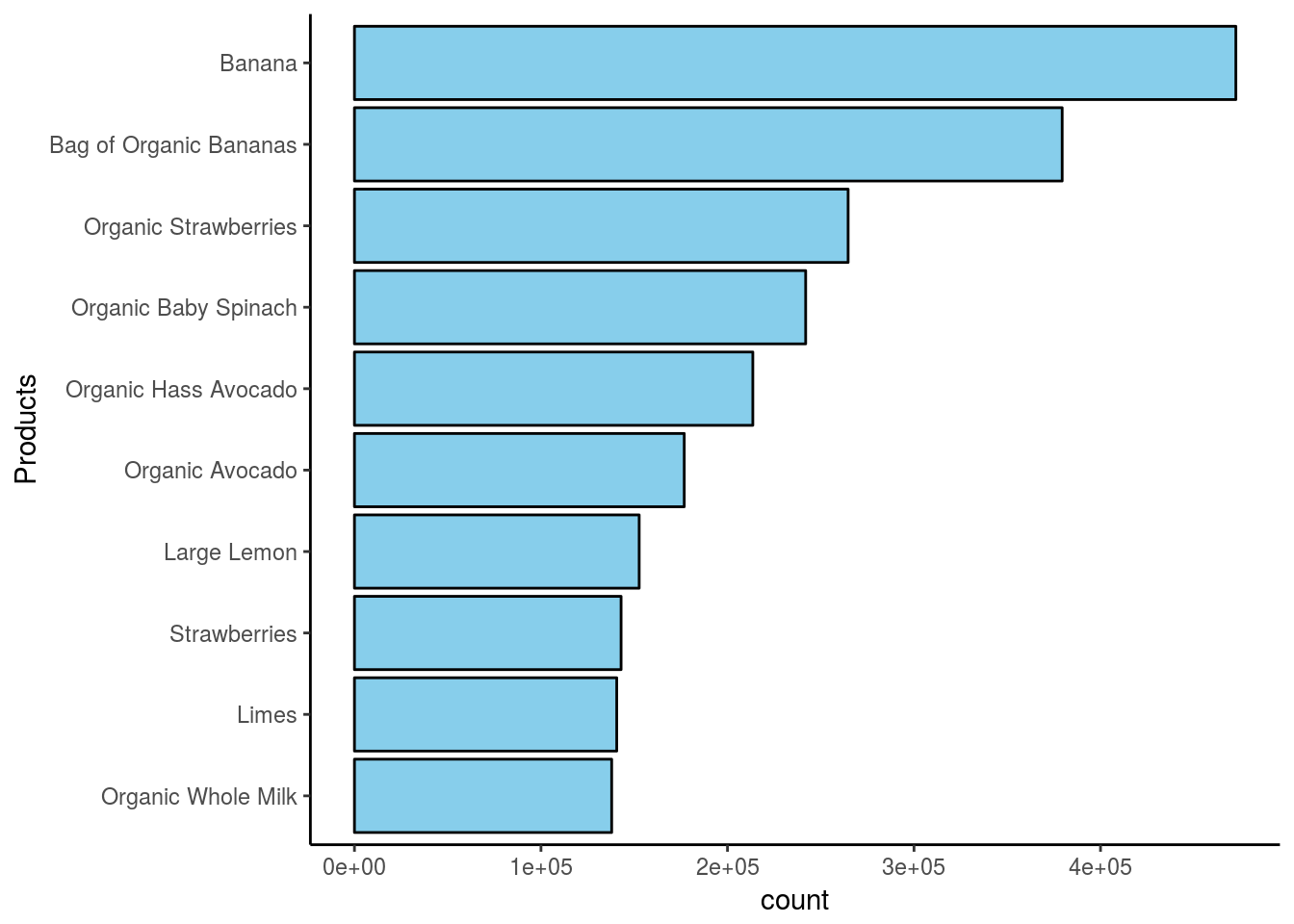
Banana is the most ordered products, Avocado and Limes also makes it to the top ordered products. That should be great for the stores I guess because bananas have a comparably lower shelve life
Which products are more likely to be re-ordered?
Should we expect to see food with addictive substances having a higher score?
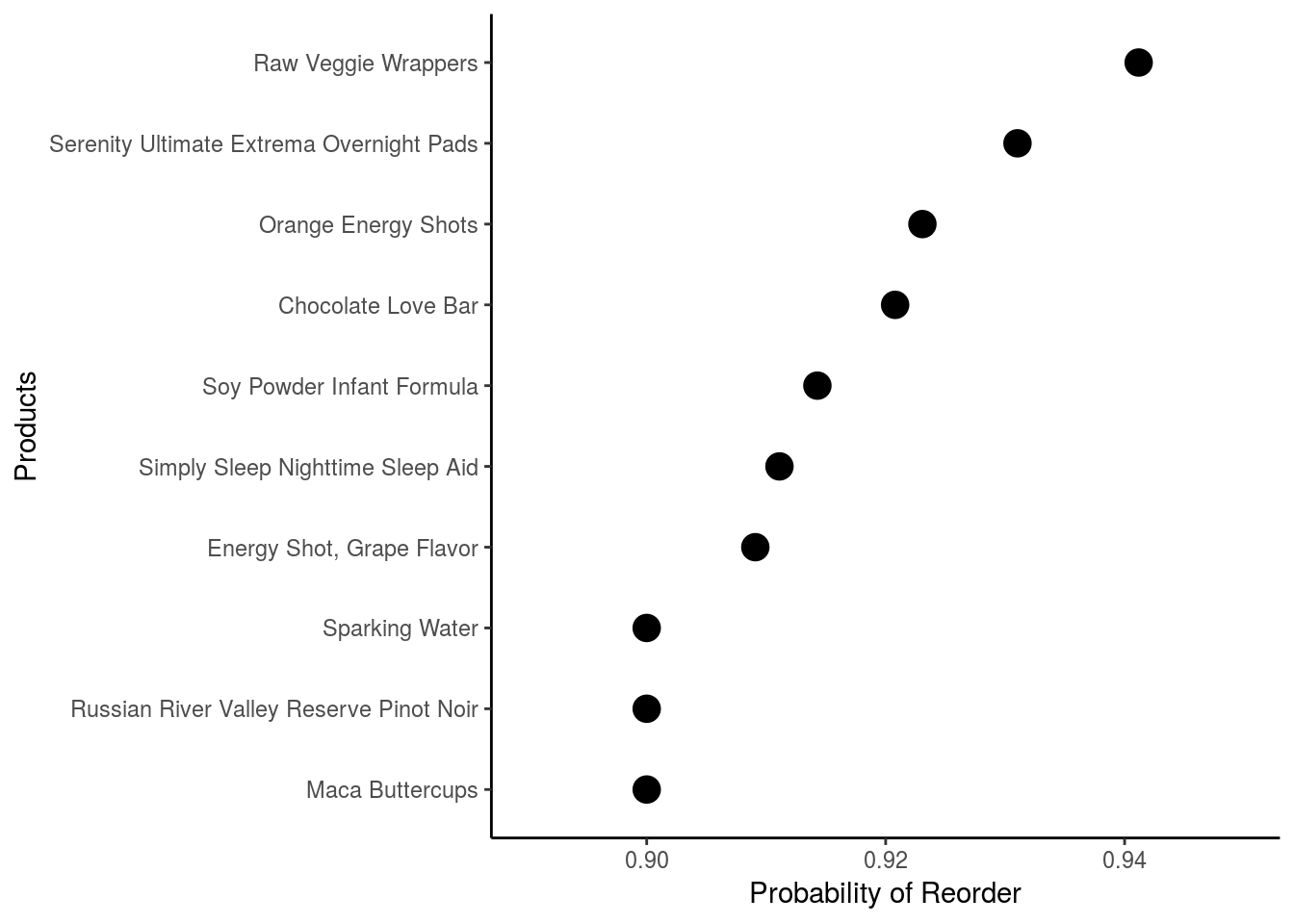
A consumer who purchases the above products have a very high probability of re-ordering the same products. True to my hypothesis, we find energy shots which are known to contain a high amount of caffeine present in the list. Also studies have shown chocolate have several substances that can make it feel addictive
Which day of week do customers make the most orders:
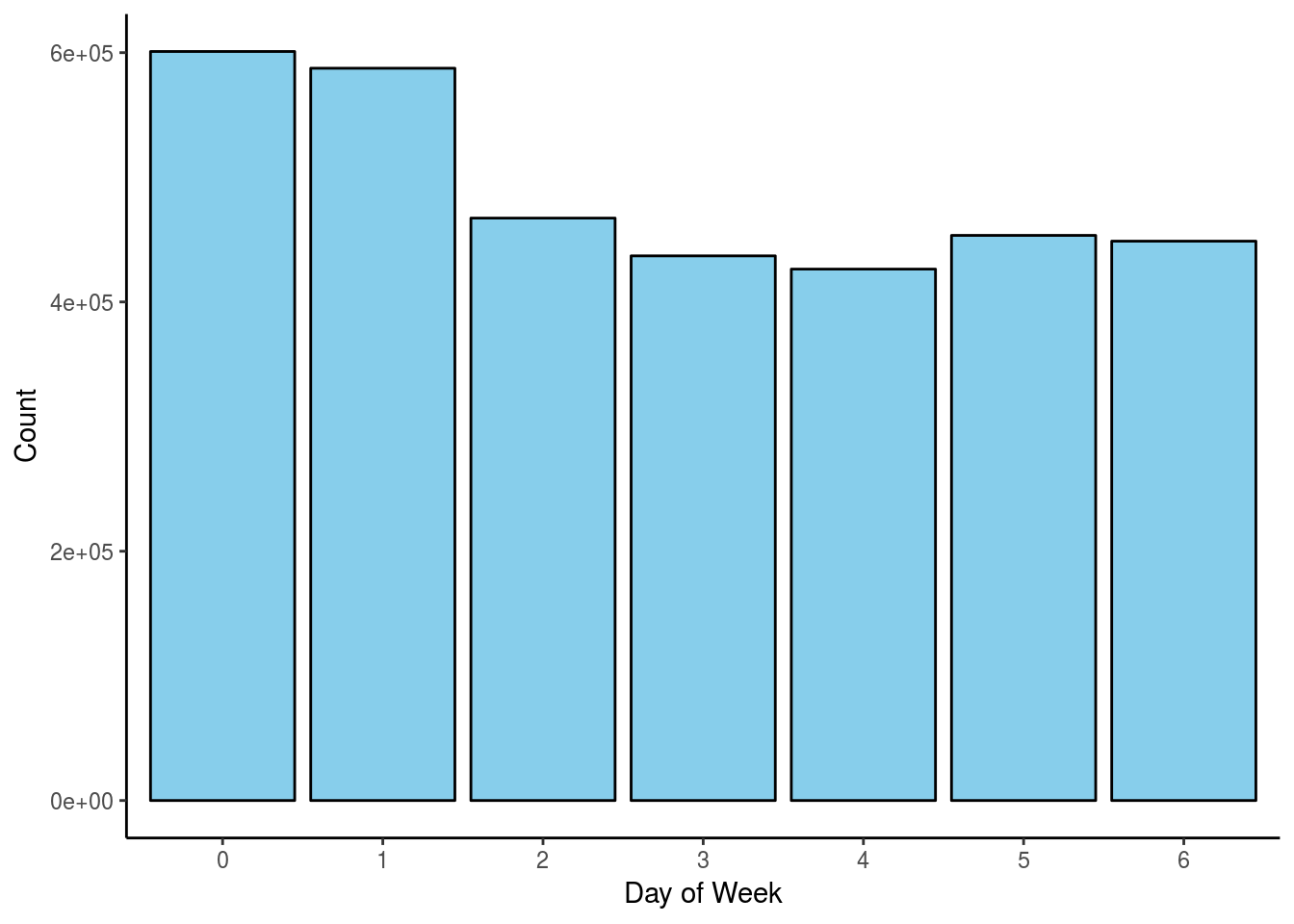
Because the data was anonymized we cannot state with absolute certaninty but can safely assume that the high bars represents weekends. Saturdays and sundays are the most popular days for online shopping. I suppose because People would go to work on weekdays, they’ll have less time shopping.
Which hour of the day does most orders occur?
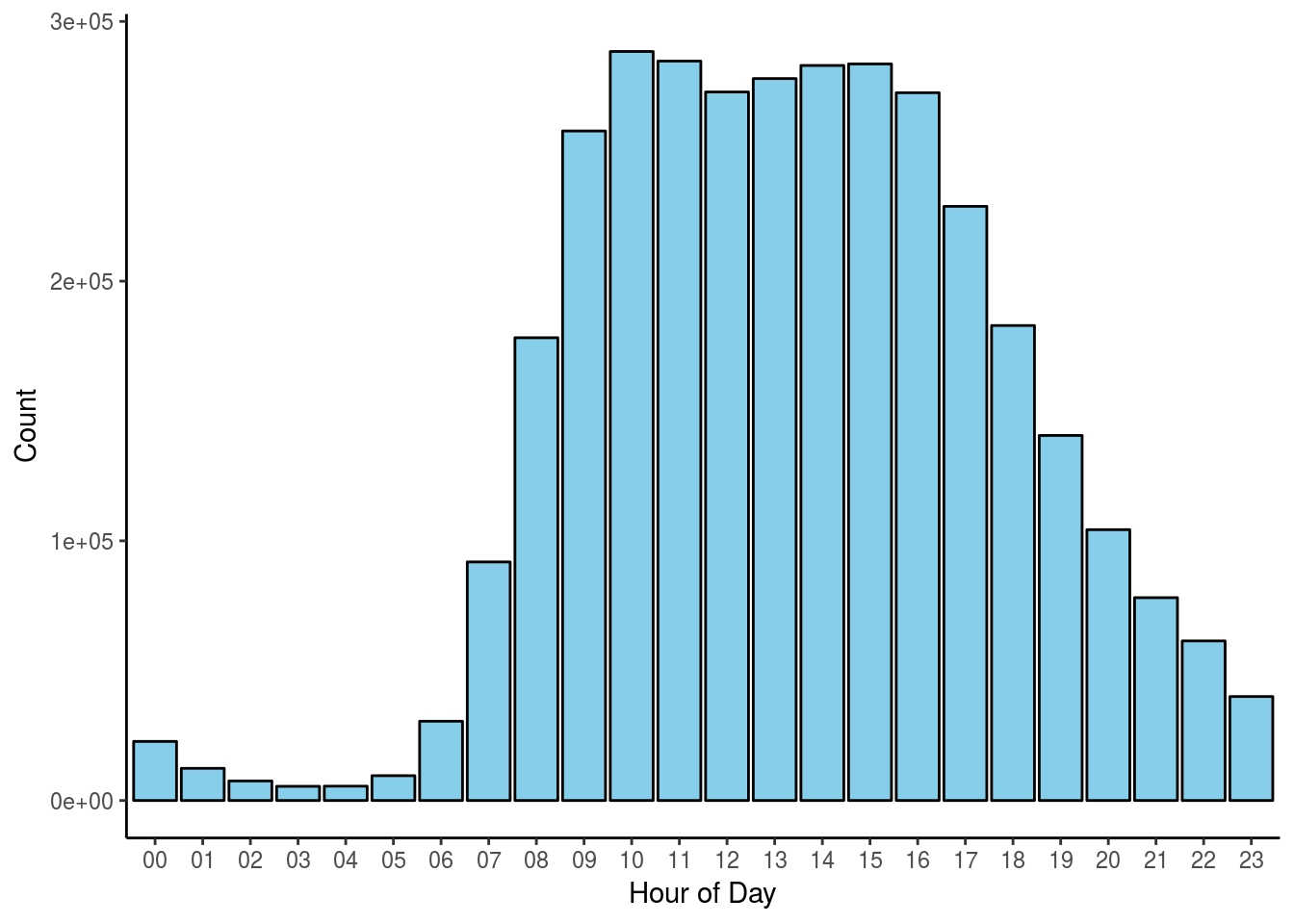
I think we can understand that consumers are more likely to shop during the day. Most folks sleep at night - unless you are a night watcher :-)
Which product are more likely to be ordered late at night?
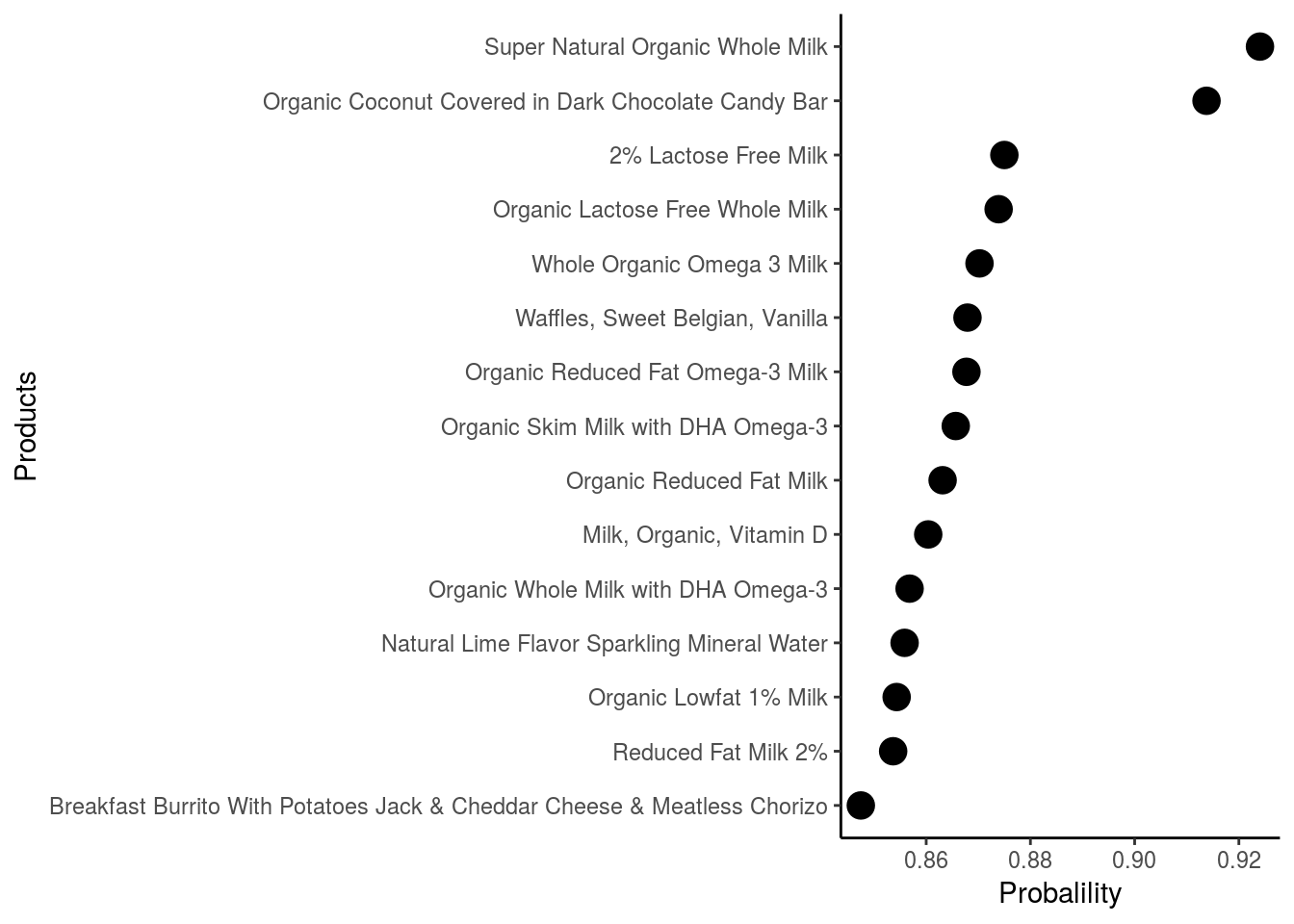
Which product are more likely to be ordered very early in the morning?
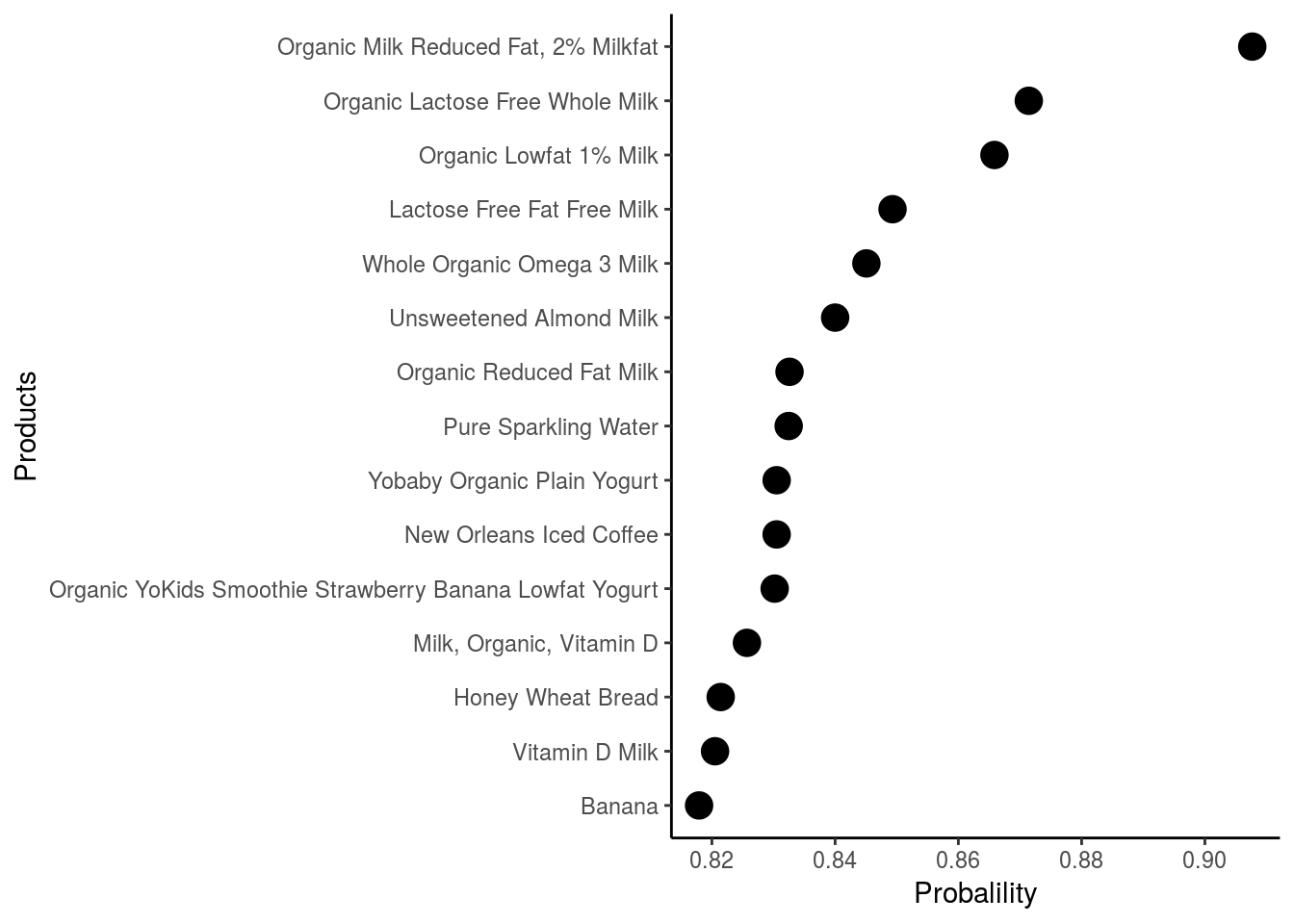
Diary products are more commonly ordered at night and early morning in comparison with the other products. I guess because they are often taken for breakfast
Which aisle makes the most sales:
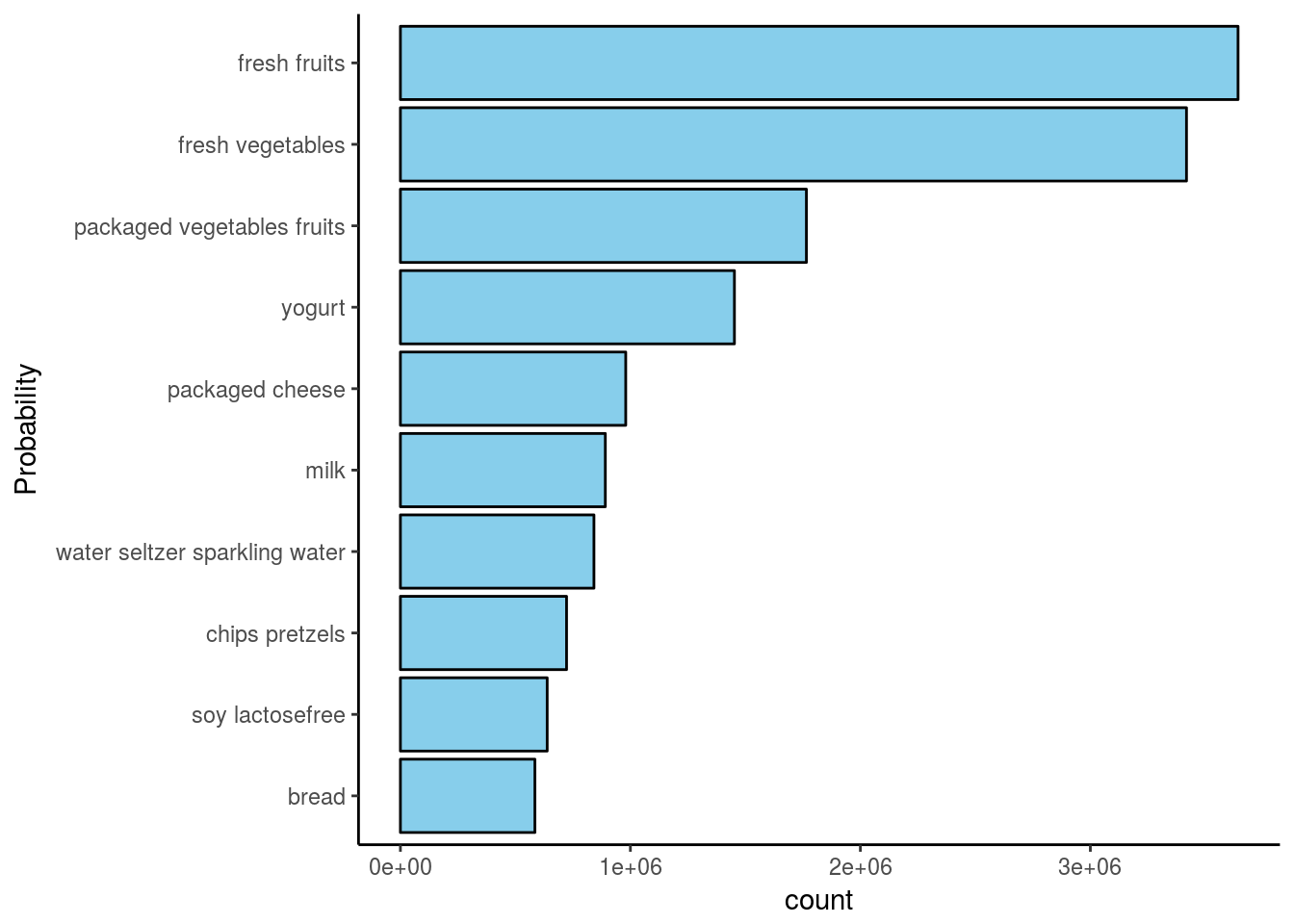
Fresh fruits and fresh vegetables makes the top of the list.
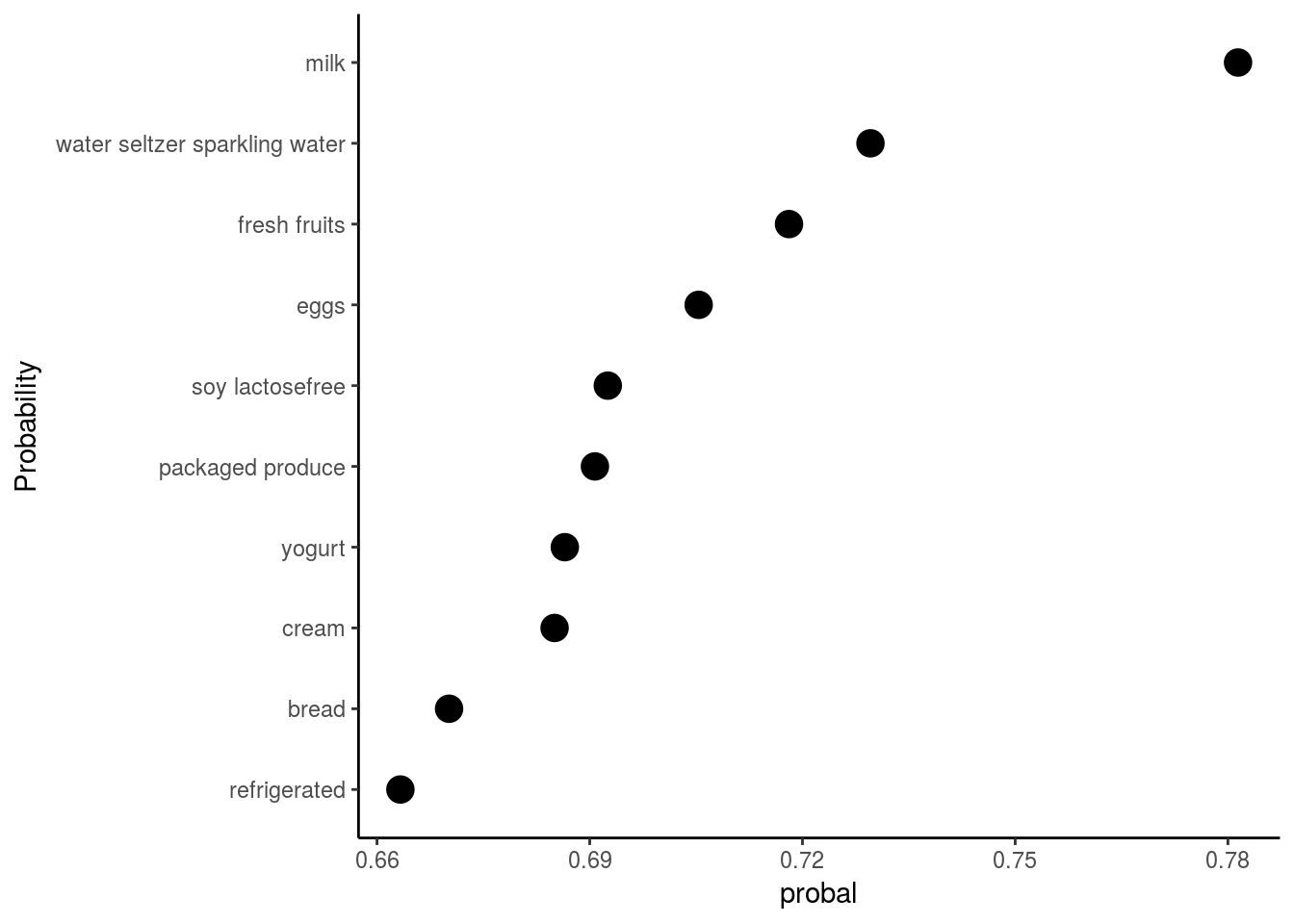
Which aisle gets the highest reorder?
Again diary products and fresh fruits have a high probability to be reordered by customers who make a purchase
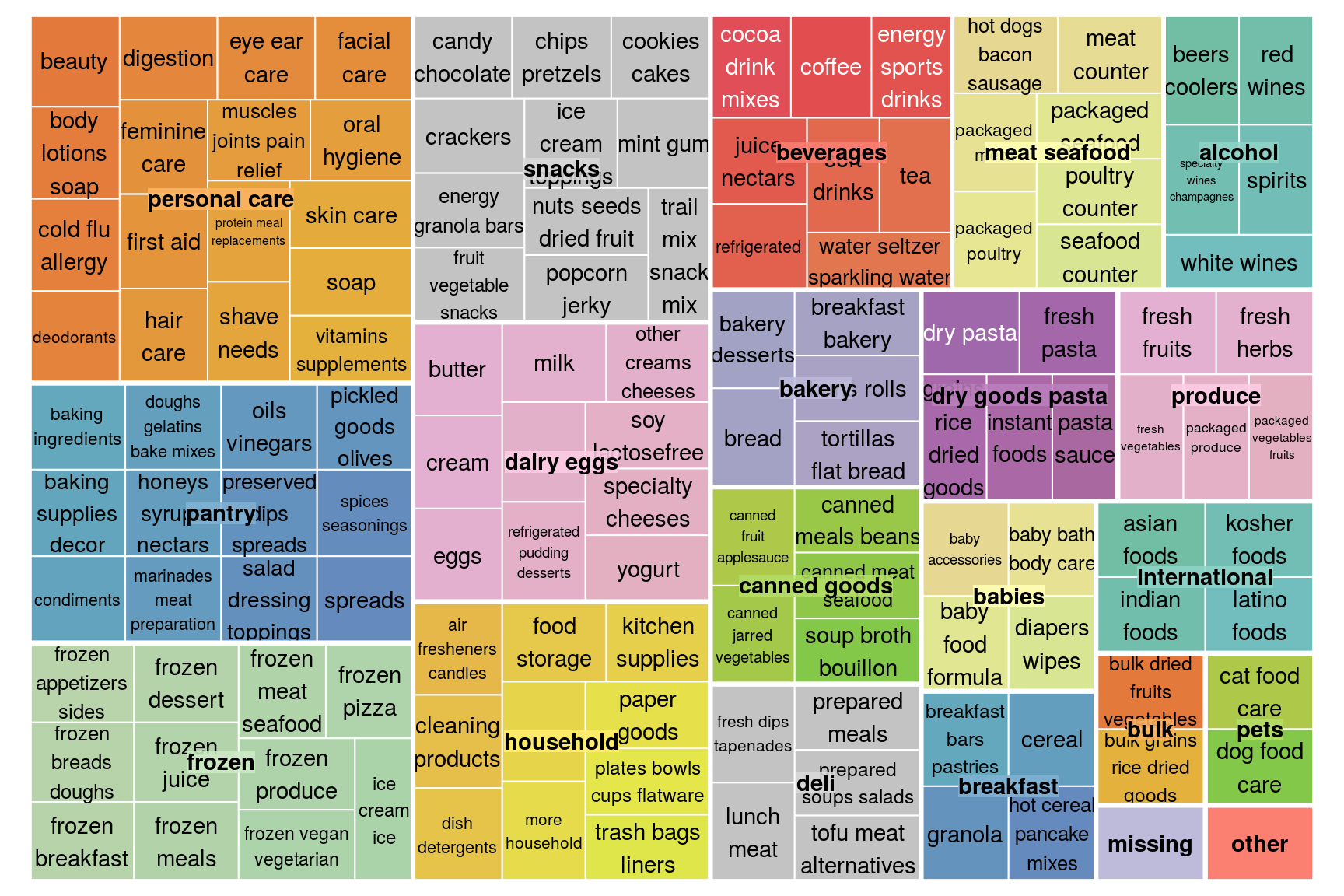
Let’s see how the aisle are distributed among the various departments. It appears the personal care department controls majority of the aisle but sell less products when compared to the produce department
How many Products are sold within each department?
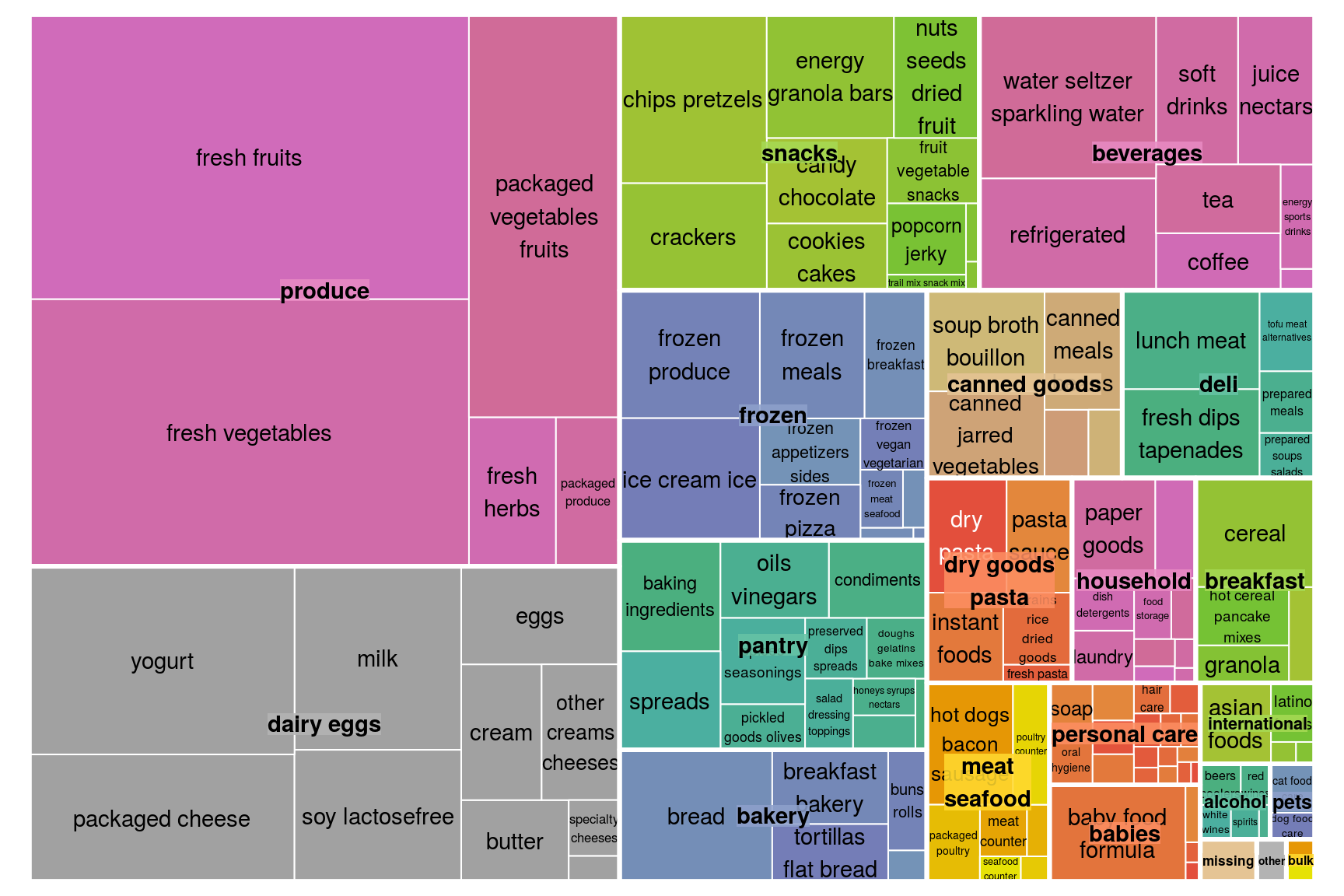
The size of the boxes signifies the number of products sold in each department
This hopefully helps to understand the data more and we can smoothly move on to build our model. See you soon with some more cool data stuff!

